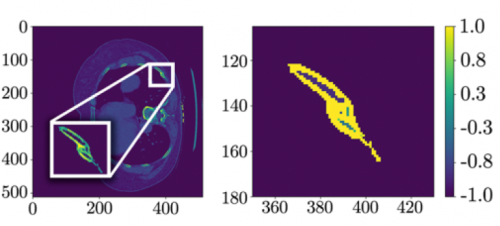
It is becoming clearer and clearer that patients with suspicion for fractures of the thoracic (T) and lumbar (L) spine should be imaged only with CT scan. Conventional imaging just doesn’t have enough sensitivity, even in younger patients with healthy bones. But when we obtain CT of the T&L spines there is a choice: just look at the axial / helical slices, or have the computer reconstruct additional images in the sagittal and coronal planes. The belief is that this multiplanar imaging will assist in finding subtle fractures that might not be seen on axial views.
The group at Rutgers in New Jersey tried to determine if adding the reconstructions amounted to overkill. They performed a retrospective review of patients at their Level I center over a six-year period. They focused on studies performed in patients who had T and/or L fractures who also had both CT of the chest, abdomen, and pelvis (CAP) and thoracic and lumbar reconstructions. Additional data were obtained from a review of the medical record and trauma registry.
Here are the factoids:
- A total of 494 patients had both CAP and reconstructions
- There were 1254 fractures seen on CAP, and an additional 129 fractures seen with recons (total of 1394)
- The majority of additional injuries not detected on CT CAP were transverse process fractures
- The number of other fracture patterns not seen on CT CAP were statistically “not significant”
- However, these numerically “not significant” fractures included 51 vertebral body fractures, 6 burst fractures, 3 facet fractures, and 2 pedicle fractures
- No unstable fractures were missed on CT CAP
- More MRIs were performed in the patients who had recons, there were more spine consultations, and 11% underwent operative fixation vs. 2% for CTA only (!!)
The authors concluded that CT CAP alone was sufficient to identify clinically significant thoracic and lumbar fractures. They also stated that clinically insignificant injuries identified with reconstructions were more likely to undergo MRI and use excess resources. They urged us to be selective with the use of T&L reformats.
Bottom line: Wow! I have a lot of questions about this abstract! And I really disagree with the findings.
You studied fewer than 500 patients with T or L spine fractures over a six year period. This is only about 80 per year, which seems very low. This suggests that many, many patients were being scanned without recons to start with. How did patients get selected out to get recons? Were there specific criteria? I worry that this could add some bias to your study.
The number of fractures seen only on the recon views besides transverse process fractures were deemed “statistically insignificant.” However, looking at the list of them (see bullet point 5 above) they don’t look clinically insignificant. It’s no wonder that recons resulted in more consults, MRI scans, and spine operations!
I worry that your conclusion is telling us to stop looking for fractures so we won’t use so many additional resources. But their use may be in the best interest of the patients!
Here are my questions and comments for the presenter/authors:
- Why did you decide to do this study? I didn’t realize that not doing the recons was a thing in major blunt trauma. Was there some concern that resources were being wasted? Was there an additional cost for the reconstructions?
- How many patients only received CT CAP? The greater the number of these, the higher the probability that some non-random selection process is going on that might bias your findings.
- How did you get separate reports for the non-reconstructed images? Did you have new reads by separate radiologists? Typically, the report contains the impression for the entire study. It would be unusual for the radiologist to comment on the non-recon images, then add additional findings from just the reconstructions.
- Doesn’t the increased numbers of spine consults, MRIs, and operative procedures in the patients with reconstructions imply that these otherwise occult fractures needed clinically important additional attention?
I worry that readers of this abstract might take away the wrong message. Unless there is some additional compelling data presented, this study is certainly not enough to make me change my practice!
Reference: UTILITY OF CT THORACOLUMBAR SPINAL RECONSTRUCTION IMAGING IN BLUNT TRAUMA. EAST 2023 Podium paper #20.