The TRISS score is the great grand-daddy of probability of survival prediction in trauma, first introduced in 1981. It is a somewhat complicated equation that takes the injury severity score (ISS), revised trauma score (RTS), and age and cranks out a probability between 0 and 100%. Over the years, this system has been well validated, and its shortcomings have been elucidated as well.
Many authors have attempted to develop a system that is better than TRISS. Years ago, there was the New-TRISS. And back in the day (early 1990s) I even developed a neural network to replace TRISS. In general, all of these systems may improve accuracy by a few percent. But it has never been enough to prompt us to ditch the original system.
The group at the University of California at Los Angeles developed a machine learning algorithm using ICD-10 anatomic codes and a number of physiologic variables to try to improve upon the original TRISS score. They analyzed three years of NTDB data and attempted to predict in-hospital survival.
Here are the factoids:
- The authors used over 1.4 million records to develop their model
- Overall, 97% of patients survived, and survivors tended to be younger, have higher blood pressure, and have sustained a blunt mechanism (no surprises here at all)
- The ROC C-statistic for the false positive rate was better with the machine learning model (0.940 vs 0.908), as was the calibration statistic (0.997 vs 0.814)
Here is the ROC curve for machine (blue) vs TRISS (yellow):
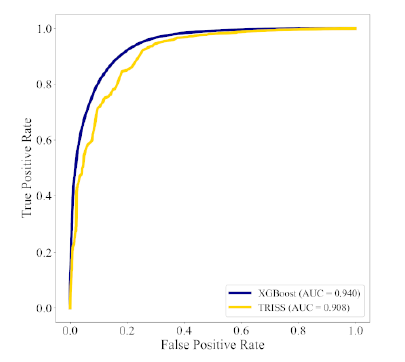
The authors conclude that the machine learning model performs better than TRISS and that it may improve stratification of injury.
Bottom line: This study is one of many attempting to improve upon good old TRISS probability of survival. Why have there been so many attempts, and none that have appeared to “stick?” Here are my thoughts:
- They are complicated. Sure, the original TRISS equation is slightly complicated, but it’s nothing close to a machine AI algorithm.
- The inner workings are opaque. It’s not very easy to “open the box” and see which variables are actually driving the survival calculations.
- The results are only as good as the training data. There is a real skew toward survival here (97%), so the algorithm will more likely be right in guessing that the patients will survive.
- The improvements in these systems are generally incremental. In this case the ROC value increases from .908 to .940. Both of these values are very good.
In general, any time a new and better algorithm is introduced that shows much promise, someone wants to patent it so they can monetize the work. Obviously, I don’t know anything about the plans for this algorithm. Somehow I doubt that many centers would be willing to abandon TRISS for an incremental improvement that may not be clinically significant at any price.
Here are my questions for the authors and presenter:
- Please detail how you selected the variables to enter into the machine learning algorithm. Were they chosen by biased humans who had some idea they might be important, or did the AI comb the data and try to find the best correlations?
- Be sure to explain the ROC and calibration statistics well. Most of the audience will be unfamiliar.
- Are you using your model in your own performance improvement program now? If so, how is it helping you? If not, why?
Fascinating paper! Let’s here more about it!
Reference: ICD-10-BASED MACHINE LEARNING MODELS OUTPERFORM THE TRAUMA AND INJURY SEVERITY SCORE (TRISS) IN SURVIVAL PREDICTION, EAST 35th ASA, oral abstract #38.