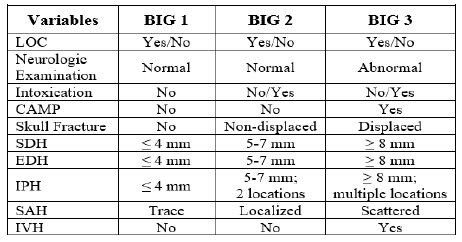
The Brain Injury Guidelines (BIG) were developed to allow trauma programs to stratify head injuries in such a way as to better utilize resources such as hospital beds, CT scanning, and neurosurgical consultation. Injuries are stratified into three BIG categories, and management is based on it. Here is the stratification algorithm:

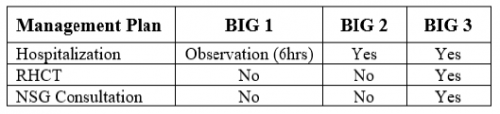
And here is the management algorithm based on the stratification above:
The AAST BIG Multi-Institutional Group set about validating this system to ensure that it was accurate and safe. They identified adult patients from nine high level trauma centers that had a positive initial head CT scan. They looked at the the need for neurosurgical intervention, change in neuro exam, progression on repeat head CT, any visits to the ED after discharge, and readmission for the injury within 30 days.
Here are the factoids:
- About 2,000 patients were included in the study, with BIG1 = 15%, BIG2 = 15%, and BIG3 = 70% of patients
- BIG1: no patients worsened, 1% had progression on CT, none required neurosurgical intervention, no readmits or ED visits
- BIG2: 1% worsened clinically, 7% had progression on CT, none required neurosurgical intervention, no readmits or ED visits
- All patients who required neurosurgical intervention were BIG3 (20% of patients)
The authors concluded that using the BIG criteria, CT scan use and neurosurgical consultation would have been decreased by 29%.
Bottom line: This is an exciting abstract! BIG has been around for awhile, and some centers have already started using it for planning the management of their TBI patients. This study provides some validation that the system works and keeps patients safe while being respectful of resource utilization.
My only criticism is that the number of patients in the BIG1 and BIG2 categories is low (about 600 combined). Thus, our experience in these groups remains somewhat limited. However, the study is very promising, and more centers should consider adopting BIG to help them refine their management of TBI patients.
Reference: VALIDATING THE BRAIN INJURY GUIDELINES (BIG): RESULTS OF AN AAST PROSPECTIVE MULTI-INSTITUTIONAL TRIAL. AAST 2021, Oral abstract #25.