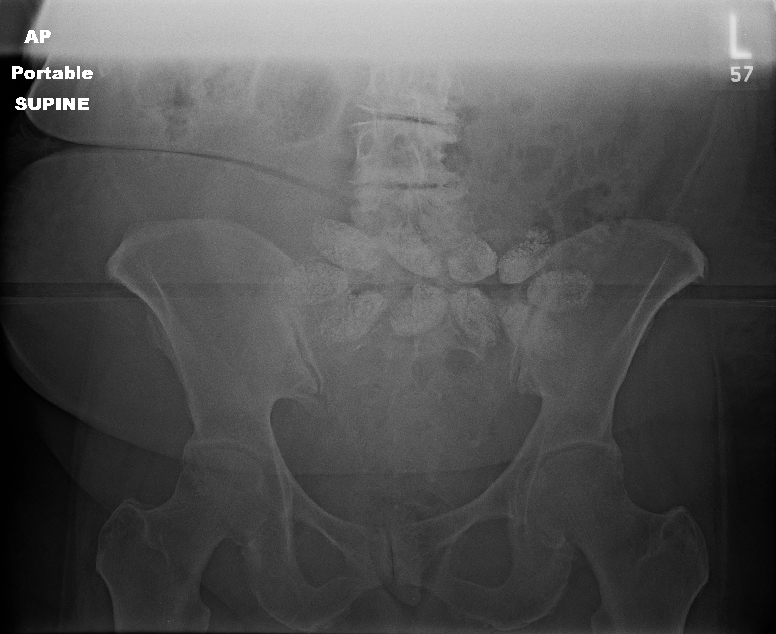
We’ve come a long way in our available treatments to slow or stop bleeding from pelvic fractures. Let’s work our way through the list in today’s post, then look critically at two of the newcomers in the next one.
Pelvic binders. Long ago, these were just sheets wrapped around the patient and secured with clamps. 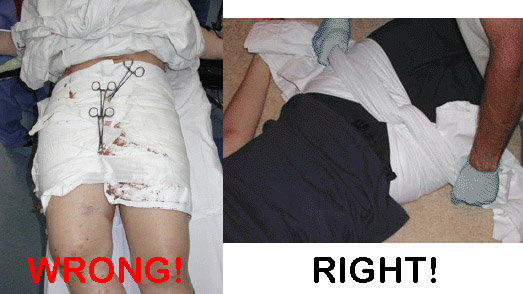
They were rather crude, as you can see. So of course, several enterprising companies began to offer commercial binders that were easier to place and secure.
Of note in the photo above, the wrap on the left is totally wrong. It is too wide and extends too high, so will not provide effective compression. The image on the right shows proper placement low across the greater trochanters. It is also not secured using metal clamps which may interfere with x-ray imaging.
External fixation of the pelvis. This usually involved a call to your friendly orthopedic surgeon. It could be applied in either the trauma bay or the operating room.
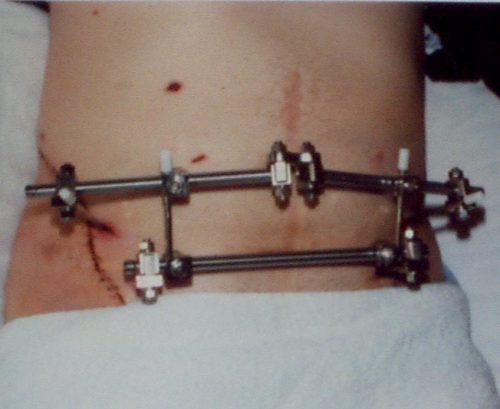
This image also shows improper technique. The horizontal bar should be angulated downwards over the pubis so it will not interfere with the trauma surgeon’s approach to laparotomy.
Internal pelvic packing + internal iliac artery ligation. Since surgeons didn’t have many other good tools, they could actually operate! Unfortunately, neither of these worked terribly well. The laparotomy pads could decompress upwards out of the pelvis and the internal iliac arteries have lots of collateral branches that permit ongoing bleeding from pelvic bones.
Angioembolization. Arterial bleeding from the pelvis occurs more often than you think (upwards of 50% of major pelvic injuries). Angiography and embolization can work very well. Unfortunately they are not suitable for unstable patients since IR suites are poor resuscitation areas. Many trauma centers do not have hybrid operating rooms where hemodynamically compromised patients can be taken for combined IR and open procedures if needed. So unstable patients must go to a regular OR first to attempt stabilization.
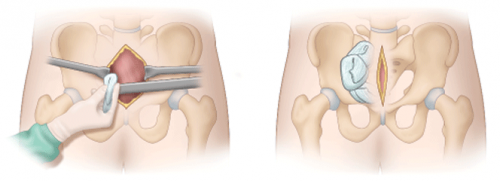
Preperitoneal packing. This is the new OR procedure kid on the block. Instead of placing packs in the pelvis, they are placed next to the broken pelvic bones but just outside the peritoneum. This permits better tamponade, and the intraperitoneal viscera push out against the packs to help decrease bleeding.
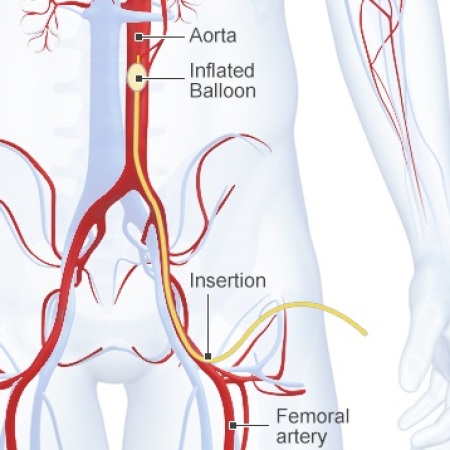
Zone 3 REBOA. And this is the very newest kid on the block. The balloon tipped catheter is inserted to a level above the aortic bifurcation but below the visceral and renal vessels. This is essentially a non-selective, temporary ligation of not just the internal iliac arteries, but everything distal to the aorta. It can be performed in the ED to dramatically slow blood loss, providing more time to get the patient to the OR where more definitive hemorrhage control can be provided (using many of the above techniques).
In my next post, I’ll take a closer look at the effectiveness of preperitoneal packing vs angioembolization.